

서론
앞선 포스팅에서는 Data Curation을 위해 데이터 로드하는 것 까지 진행했다. 이번에는 데이터 로딩 이후에 가공하는 과정을 진행하고자 한다. 참고로 가공에는 무조건적인게 없다. 데이터를 살펴보고 데이터에 따라 어떻게 가공해야될지 판단하는것은 본인의 몫이다. 그리고 시작에 앞서 이번 파인 튜닝의 목적은 제품 가격을 예측하는 LLM을 만드는 것임을 알리고자 한다. 물론 직접 데이터 분석해서 모델링할 수도 있지만 LLM도 Regression 기반이기 때문에 가능하기 때문이다. 다만 다른게 있다면 데이터 분석은 어떤한 변수를 주면 예측한다는건데 LLM은 query를 주면 그에 맞는 예측 답변을 말할 것이다.
데이터 셋 살펴보기
데이터 셋을 로드 하면 무엇이 들어있는 지 알아야 된다. 이는 다운받는 과정에서 데이터 카드에 적혀있다. 그럼 여기서 내 데이터에 필요한 걸 판단해보자. 다음은 데이터셋에 적혀있는 내용이다. 우선 내가 하려는 것을 명확하게 해야된다. 어떤식으로 학습시키고자 하는가? 앞서 말했듯 가격을 예측하는 것이기 때문에, llm에게 던질 프롬프트에 의미가 없는것들을 추려내고자 한다.
{'main_category': 'All Beauty',
'title': 'Howard LC0008 Leather Conditioner, 8-Ounce (4-Pack)',
'average_rating': 4.8,
'rating_number': 10,
'features': [],
'description': [],
'price': 'None',
'images': {'hi_res': [None,
'https://m.media-amazon.com/images/I/71i77AuI9xL._SL1500_.jpg'],
'large': ['https://m.media-amazon.com/images/I/41qfjSfqNyL.jpg',
'https://m.media-amazon.com/images/I/41w2yznfuZL.jpg'],
'thumb': ['https://m.media-amazon.com/images/I/41qfjSfqNyL._SS40_.jpg',
'https://m.media-amazon.com/images/I/41w2yznfuZL._SS40_.jpg'],
'variant': ['MAIN', 'PT01']},
'videos': {'title': [], 'url': [], 'user_id': []},
'store': 'Howard Products',
'categories': [],
'details': '{"Package Dimensions": "7.1 x 5.5 x 3 inches; 2.38 Pounds", "UPC": "617390882781"}',
'parent_asin': 'B01CUPMQZE',
'bought_together': None,
'subtitle': None,
'author': None}
이중에서 딱 보고 의미가 없어 보이는건 아무래도 url이다. url을 안다고 llm이 가격을 예측하는데 나은 무언가가 안나올건은 자명하기 때문이다. 저런 의미 없는 문자들의 향연은 도움이 안되는 것을 넘어 오히려 안 좋은 영향을 끼친다. 비슷한 이유로 parent_asin(제품의 부모 ID라고 데이타셋 카드 내 변수 설명에 나와있음)와 details 내 UPC도 안 가져올 것이다. 하지만 UPC 경우는 details에 들어가있고 이건 유효해 보이므로(아직까진) 살려둘 것이다. features는 bullet point로 된 설명이므로 중요하다. store가 애매한데 store명이 곧 product 회사일 경우가 있고 아닐 수도 있다. 누구는 이걸 무의미하다고 보겠지만 일단 나는 유의미하다고 판단했다. 내 경험상 보통 같은 제품이면 공식이 더 비싸긴 했기 때문이다. 아무튼 이런식으로 지울걸 지우면 다음과 같이 나온다.
{'main_category': 'All Beauty',
'title': 'Howard LC0008 Leather Conditioner, 8-Ounce (4-Pack)',
'average_rating': 4.8,
'features': [],
'description': [],
'price': 'None',
'videos': {'title': [], 'url': [], 'user_id': []},
'store': 'Howard Products',
'categories': [],
'details': '{"Package Dimensions": "7.1 x 5.5 x 3 inches; 2.38 Pounds", "UPC": "617390882781"}',
}데이터 분포 살펴보기
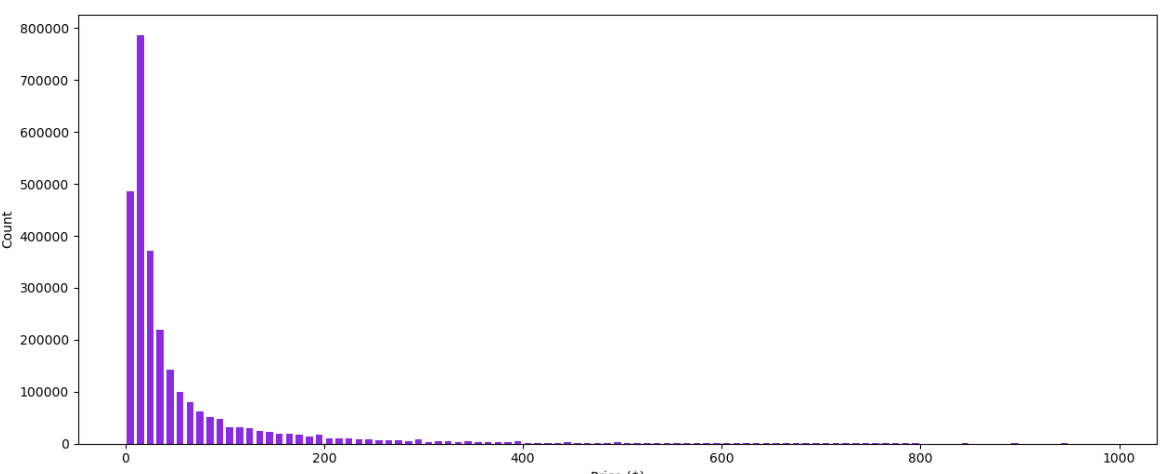
데이터를 로드한 뒤, 가격의 분포를 보면 다음과 같다. 매우 매우 편향적인 모습을 띄고 있다. 그래서 가격에 따라 벨런스를 맞추기 위해 카테고리별로 개수를 보니 automotive가 약 100만개, Electronics가 약 45만개, Office_Prodicts가 25만개, Tools_and_Home_Improvement가 55만개, Cell_Phones_and_Accessories가 25만개, Toys_and_Games가 34만개, Appliances가 3만개정도 됐다. 이 벨런스를 맞추기 위해서 Automotive를 제외한 나머지 데이터셋에 가중치를 주고자 한다.
스토어 이름이 제품명에 들어가 있는지 확인
각 카테고리마다 가중치를 주기 전에, 스토어 명이 제품명에 들어가 있을 시 공식몰 내지 해당 브랜드만 파는 제품사일 것 이라고 추측했다. 그리고 이거는 스토어 명에서 5글자만 끊고 이게 제품 title에 들어갔는지 여부를 체크했다. 전부 다 집어넣은 건 아닌 이유는 'abc official store'처럼(내가 지어냄) abc 이후의 글자는 제목에 안들어갔을 확률이 높기 때문이다. 그리고 알아보니 제품명에 들어가있는지 확인한 결과, 스토어 이름이 제품명에 들어가 있을 때 평균 가격이 67.3, 없을때가 38.1로 매우 매우 유의하게 높았다. 그래서 이 역시 프롬프트에 집어 넣기로 했다.
비디오가 포함됐는지 여부 확인
내 쇼핑 경험상 비디오는 있는 것들이 더 비싼 경우가 많았다. 그래서 가격을 측정하는데 유의미한 무언가가 있을 것이라 판단하여 그래프를 보았다. 그래서 url의 존재 여부를 체크해서 있으면 프롬프트에 video exists라고 적었다. (has video라고 하려고 했으나 exist가 잘 안쓰는 글자여서 좀 더 의미있게 판단하지 않을까라는 기대였다.) 그렇게 분석을 한 결과 처음에는 한 카테고리에서만 분석 했을때 비디오 있는게 평균+2정도 없는게 -2 달라로 미비하나 의미있는 차이를 보였다. 그런데 전체 데이터에서 확인한 결과 오히려 비디오가 없는 표본에서 더 큰 가격이 나왔다. 그래서 얜 있는 버전과 없는 버전의 데이터셋을 각각 만들었다. 혹시 모르기 때문이다.
가중치 주기 1
가중치를 주기 위해 slot이라는 변수에 각 가격대 별로 list를 담을 딕셔너리를 만든다. 그 후 weight을 주려는데, 위에서 계산한 표본의 개수와 반비례하게 가중치를 주겠다. 참고로 random.seed를 한 건 돌릴때마다 일정한 값을 보면서 확인하기 위함이다.
np.random.seed(42)
random.seed(42)
sample = []
for i in range(1, 1000):
slot = slots[i]
if i>=240:
sample.extend(slot)
elif len(slot) <= 1200:
sample.extend(slot)
else:
weights = np.array([1 if item.category == 'Automotive' else
2.22 if item.category == 'Electronics' else
1.82 if item.category == 'Tools_and_Home_Improvement' else
4 if item.category == 'Office_Products' else
4 if item.category == 'Cell_Phones_and_Accessories' else
2.9 if item.category == 'Toys_and_Games' else
30 if item.category == 'Appliances' else
14
for item in slot])
weights = weights / np.sum(weights)
selected_indices = np.random.choice(len(slot), size=1200, replace=False, p=weights)
selected = [slot[i] for i in selected_indices]
sample.extend(selected)위 코드의 과정은 1. 240 usd 이상과 해당 가격대에 1200개 미만인 것들을 소수로 생각해서 다 반영하겠다는 의미다. 그말인 즉슨 소수가 아니라고 판단되는 것들은(else 이하) weight을 줘서 조정을 한것임. 이렇게 하면 아래와 같이 그래프의 skewness가 개선된 상태가 된다. 제일 처음 데이터 분포 살펴보기에서 보여준 그래프와 비교를 하면 알 수 있다. 중간중간 튀는 값들은 n99 usd로 파는 것으로 추정된다. 199달러, 399달러 이렇게 파는 경우 말이다.

가중치 주기 2
사실 난 저기에서 만족하지 않았다. 왜냐, automotive 데이터가 너무 많은 나머지 가중치를 30이나 줘도 결과에 미미했기 때문이다. 그래서 내가 한 방법은 위에 코드에서 가중치에 다 10씩 곱했다. 아래와 같이 말이다. 그러니까 이제서야 유의미한 변화가 일어났다. 사실 이렇게 억지로 가중치를 높인게 나중에 어떻게 반영될 지 모르겠다.
weights = np.array([1 if item.category == 'Automotive' else
22.2 if item.category == 'Electronics' else
18.2 if item.category == 'Tools_and_Home_Improvement' else
40 if item.category == 'Office_Products' else
40 if item.category == 'Cell_Phones_and_Accessories' else
29 if item.category == 'Toys_and_Games' else
300 if item.category == 'Appliances' else
140
for item in slot])
끝으로
이번에는 데이터를 수집한 뒤 간단히 분석하는 과정에 대해서 적었다. 다음 포스팅에서는 어떤식으로 프롬프트를 제작했는지에 대한 과정을 적을 것이다. 다음 포스팅은 여기로 가면 된다.
'IT, Digital' 카테고리의 다른 글
| Fine-tuning LLM (4) Load & Download data (0) | 2025.06.10 |
|---|---|
| Fine-tuning LLM (3) Item Parsing Class (0) | 2025.06.06 |
| Fine-tuning LLM (1) Data Curation과 데이터 수집 및 로드 (1) | 2025.06.03 |
| [RAG] Chroma와 FAISS 차이, 장단점 간단 정리 (0) | 2025.05.28 |
| 티스토리 하위 도메인으로 애드센스 승인 (2) 하위 도메인 블로그 에드센스 연결 및 주의사항 (1) | 2025.05.27 |